Im Zuge der Digitalisierung und entsprechend der aktuellen Datenstrategie der Bundesregierung erfreut sich das Gesundheitswesen an der Durchsetzung einer Patienten-zentrierten Verwaltung von Gesundheitsdaten, die durch das Digitale-Versorgung-Gesetz (DVG), dem Patientendatenschutz-Gesetz (PDSG) und der Datentransparenzverordnung (DaTraV) mittels der Verankerung in §363 SGB V juristisch adressiert werden. Ein wichtiger Bestandteil dieser Gesetze sieht vor, dass die Versorgungs- und Behandlungsdaten von Patienten freiwillig unter Einhaltung der gesetzlichen Rahmenbedingungen und auf Grundlage einer Einwilligung aus der elektronischen Patientenakte und für Forschungszwecke ab Januar 2023 gespendet werden können. Hierzu sollen die Daten an ein Forschungsdatenzentrum (benannte Stelle: Bundesinstitut für Arzneimittel und Medizinprodukte - BfArM) weitergeleitet werden, welches als Datentreuhänder mit der Verwaltung der Daten betraut wird und diese der medizinischen Forschung zur Verfügung stellen soll. Kritisiert wird hierbei gegenwärtig, dass entsprechend der DaTraV ebenfalls Sozialdaten ohne eine Einwilligung oder ein Widerspruchsrecht des Versicherten von den Krankenkassen an das Forschungsdatenzentrum weitergeleitet werden sollen und Nutzungsberechtigte auf Grundlage einer Selbstverpflichtung dazu berechtigt werden die Daten an Dritte weiterzuleiten, ohne Prüfung der Nutzungsberechtigung dieser. Dies führt zu einer Gefährdung der Persönlichkeitsrechte des Datensubjekts und trägt nicht zur Förderung der Akzeptanz solcher Lösungen in der breiten Gesellschaft bei, obwohl die Verknüpfung und Analyse der gesammelten Daten durch die Forschung ein enormes Potential für Einblicke in den körperlichen und psychischen Gesundheitszustand sowie Lebensstil eines Menschen bietet. Insbesondere die Forschung zu seltenen Erkrankungen kann von einer Datenspende profitieren, da häufig durch die Seltenheit, Komplexität und Unspezifität von bestimmten Krankheitsbildern und Symptomen noch enormer Forschungsbedarf besteht und gleichzeitig die Datenlage dünn ist. Zusätzlich zeichnen sich die Krankheiten durch einen lebenslangen Verlauf mit chronischen Beschwerden und Einschränkungen der Lebensqualität aus, welche sich oftmals mit zunehmenden zeitlichen Fortschritt verstärken jedoch durch eine frühzeitige Diagnose verlangsamt oder einige Symptome gar gestoppt werden können. Diese Problemstellung gilt insbesondere für den gewählten Anwendungsfall der Schlafforschung, beschränkt sich jedoch nicht nur auf diesen und gilt für alle Leiden mit einer eingeschränkten Datenlage.
Schlafbezogene Störungen betreffen bei gleichzeitig steigender Tendenz etwa ein Drittel der Bevölkerung, sie stellen einen wesentlichen Risikofaktor für kardiale und psychische Folgeerkrankungen dar. Der weit überwiegende Teil entfällt auf Insomnie, das Schlafapnoe- und das Restless-Legs-Syndrom, welche sämtlich gut charakterisiert sind. Viele der etwa 80 Schlafstörungen treten vergleichsweise selten in Erscheinung, ihre Diagnostik würde von einer verbesserten Datenlage wesentlich profitieren. Zentrales Element der Diagnostik solcher Störungen ist die Polysomnographie im Schlaflabor, die Prozesse zur Erhebung der Daten sind hochstandardisiert. Durch die standardisierten Studienabläufe zeigen aktuell Daten von Polysomnographien eine gewisse Datenqualität auf, welche zwischen verschiedenen Schlaflaboren aufgrund von verschiedenen technischen Infrastrukturen und der Zersplitterung der Datenablage schwanken kann. Oftmals leidet die Datenqualität durch fehlende oder uneinheitliche Zusatzdaten (Daten aus der Versorgung, Scorings, Metadaten). Die in Schlaflaboren vielzählig vorhandenen klinischen Daten aus Diagnostik und Studien sind meist nicht für eine Sekundärnutzung vorgemerkt oder Einwilligungen fehlen. So ist die Nutzung dieser Daten im Kontext der Forschung ausschließlich in stark anonymisierter Form möglich und ihr Nutzungspotential wird abgeschwächt. In den letzten Jahren wurden die Datenschutzbestimmungen mehrfach verschärft, was dazu führt, dass selbst die retrospektive Auswertung eigener diagnostischer Daten zunehmend problematisch und zeitintensiv wird. Insbesondere zur Verbesserung der Therapie und Diagnostik schlafbezogener Störungen im klinischen und ambulanten Umfeld wird ein erheblicher Mehrwert dieser Daten gesehen, aber auch zur Verbesserung der Standardisierung zwischen verschiedenen Schlaflaboren und zur Gewinnung neuer Marker, um spezifische personalisierte Therapieansätze und Therapie-Kontrollmechanismen erschließen zu können und ein besseres Verständnis des Phänomens Schlaf zu gewinnen.
Darüber hinaus sieht sich die Schlafforschung mit einer Replikationskrise konfrontiert. Eine exakte Reproduktion der Ergebnisse von wissenschaftlich veröffentlichten, datengetriebenen Methoden und Ansätzen (z.B. Methoden der künstlichen Intelligenz) ist zumeist unmöglich, da der Zugang zu den verwendeten Datensätzen, aufgrund von Datenschutzeinschränkungen/-bedenken oder fehlender Einwilligung, verwehrt bleibt. Hierdurch bleibt die Aussagekraft jener Ergebnisse eingeschränkt und diese können ohne die Verfügbarkeit von aggregierten, umfangreichen Datenmengen nicht ihr volles Potential für die Forschung entfalten. Es ist daher ein ethisch einwandfreies System nötig, mit dem Patienten und Studienteilnehmende ihr informiertes Einverständnis zu einer Datennutzung dokumentieren oder es auch widerrufen können.
Die Möglichkeiten zur Patienten-zentrierten Freigabe von Daten, die im Rahmen von Regelversorgung und klinischen Studien aufgezeichnet und zur Generierung neuer Forschungsergebnisse verwertet wurden, sollen im Fokus dieses Projektes stehen und zu einer sinnhaften Sekundärnutzung beitragen. Hieraus resultierend soll ein Datenspendekreislauf geschaffen werden, welcher in Abbildung 1 veranschaulicht wird.
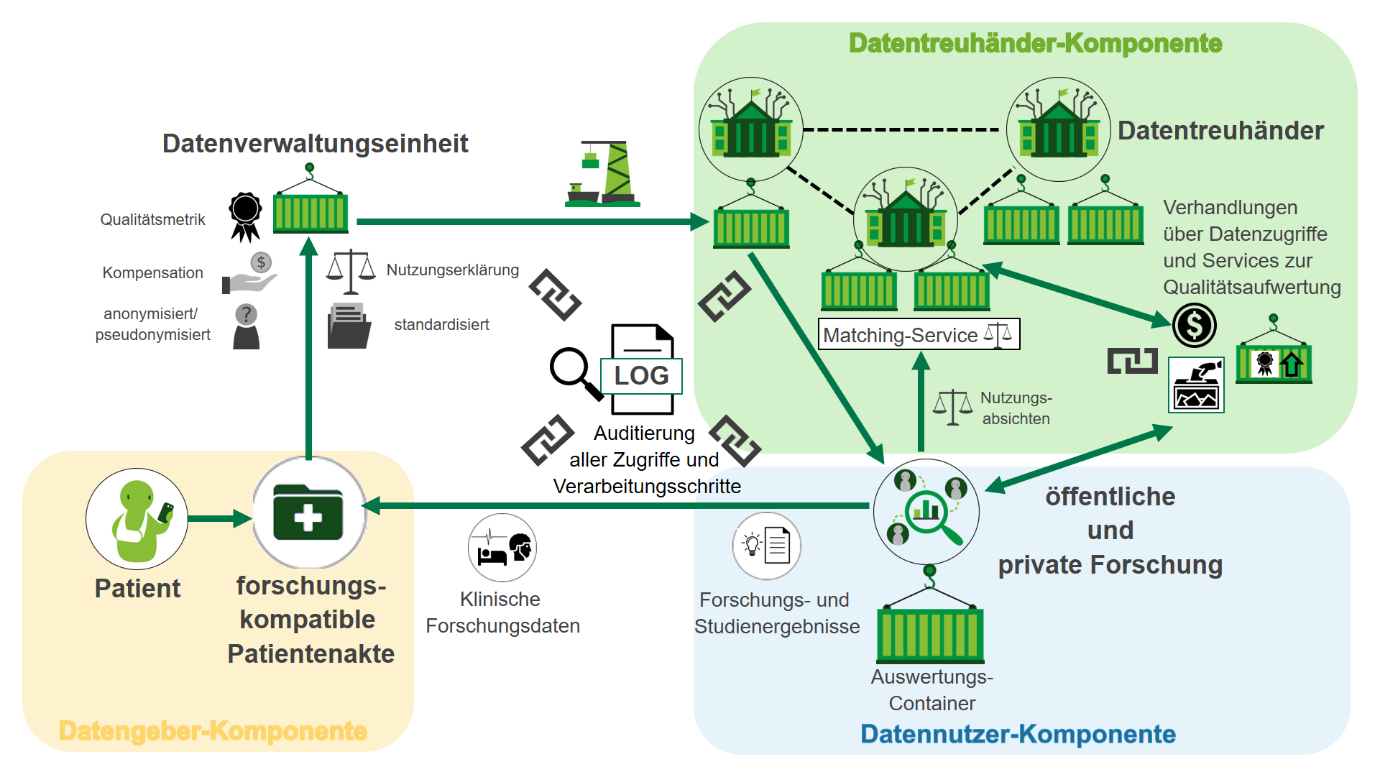
Bei Interesse an den Daten können Datennutzer (öffentliche und private Forschung) ebenso maschinenlesbare Nutzungsabsichten festlegen und Anfragen auf Datennutzung an die Datenverwaltungseinheit stellen, welche durch ein Matching-Service geprüft werden. Bei erfolgreicher Prüfung werden die Schnittstellen zu den Datenverwaltungseinheiten bzw. eine sichere Ausführungsumgebung für die vorgesehenen Analysen des Datennutzers zur Verfügung gestellt (Datennutzer-Komponente). Zur Generierung eines Anreizes für die Freigabe der Daten durch ein Datensubjekt sollen neue Erkenntnisse und Innovationen von Seiten der Forschung und Industrie zum Datensubjekt selbst zurückgespiegelt werden. Die Datenqualität von gespendeten Daten hat maßgeblich Auswirkung auf die Art und Qualität der Weiterverwendung der Daten in Forschungsstudien.4 Insofern sollte die Datenqualität im Originalzustand und bei Kombination mit weiteren Daten möglichst hoch sein. Demzufolge muss entsprechend ein Datentreuhandmodell Möglichkeiten vorsehen, welche die Messung, Aufbereitung und Dokumentation der Datenqualität im Originalzustand und entlang des gesamten Datenlebenszyklus ermöglicht. Zur Messung der Datenqualität gibt es diverse wissenschaftlich diskutierte Qualitätsindikatoren (z.B. Konkordanz, Reliabilität), welche durch die Anwendung individueller Schwellwerte zur Beurteilung der Datenqualität herangezogen werden können und sich in einem Gesamtscore zusammenfassen lassen.4 Diese könnten bereits auf Ebene der Datenverwaltungseinheiten im Datentreuhandmodell Anwendung finden. Die Aufbereitung der Daten für bestimmte Vorhaben insbesondere bei der Aggregation von Daten aus unterschiedlichen Datenquellen soll zusätzlich im Fokus dieses Projektes stehen und in den Datenspendekreislauf integriert werden.
Hierbei wäre es zum einen denkbar, dass der Datentreuhänder entsprechende Dienstleistungen zur Verfügung stellt oder aber Forscher oder Unternehmen für solche Tätigkeiten zur Verfügung stehen. Für den hierdurch resultierenden Mehraufwand muss ein Konzept geschaffen werden, welche Verhandlungen bezüglich der Zugriffe und Angebote für jene Dienste zur Qualitätserhöhung ermöglicht. Der Datengeber als Datensubjekt soll die Möglichkeit besitzen an Verhandlungen bezüglich der Zugriffe teilzuhaben und für die Bereitschaft zur Freigabe seiner Daten einen persönlichen Mehrwert zu erhalten. Auch die Nutzung der Daten über die Qualitätserhöhung und -sicherung hinaus, z.B. für die Entwicklung neuer digitaler Innovationen, könnten durch diese Art von Datenmarktplatz und Verhandlungen involviert und weiter vorangetrieben werden. Eine technische Möglichkeit als Vertrauensbasis für ein solches System kann ein Blockchain-basiertes Votingsystem sein. Hierzu können die Akteure durch eine Abstimmung ausdrücken, welche Informationen für sie relevant sind, Angebote abgeben und über die Höhe der Vergütung verhandeln. Durch die Eigenschaft der Unveränderbarkeit von Informationen auf der Blockchain kann Betrug vorgebeugt und die Stimmabgaben aufgezeichnet werden. Ergänzend hierzu sollten Optionen bezüglich der Umsetzung einer Vergütung, z.B. durch die Abbildung digitaler oder physikalischer Assets oder Dienste durch Tokenisierung, geprüft werden. Zusätzlich hängt die Datenqualität von den Methoden ab, mittels derer die Daten erzeugt wurden und von der Verfügbarkeit dazugehöriger Dokumentation und Annotation, (z.B. Auswertungen, Dokumentation des Vorhabens).
Zur kontinuierlichen Qualitätsverbesserung wird hierfür in der Praxis der sogenannte Quelldatenabgleich (Source Data Verification - SDV) durchgeführt. Hierbei erfolgt ein Abgleich von den Forschungsdaten mit der Primärdokumentation (z.B. Krankenakte), um Übertragungsfehler von der Primär- zur Studiendokumentation zu korrigieren, um so zur Verbesserung der Daten bereits bei der Erfassung beizutragen. Durch die Kombination von Studiendaten mit Gesundheitsdaten aus der Versorgung über eine Datenverwaltungseinheit kann die Korrektheit der Daten auch über die Studie hinaus validiert werden. Hierbei kann der Grad der De-Identifikation (Pseudonymisierung vs. Anonymisierung) Auswirkungen auf die Nutzbarkeit der Daten zur Qualitätsverbesserung und Sekundärnutzung haben. Aufgrund dessen sollen auch die Auswirkungen der Abwägungen, welche von einem Datengeber getroffen werden müssen, erfasst und analysiert werden, um optimale Ergebnisse erzielen zu können sowie den Datengeber über die Folgen seiner Wahl aufzuklären. Die transparente Dokumentation der Datenqualität sowie möglicher Zugriffe und Verarbeitungsschritte zur Verbesserung der Datenqualität wäre ebenfalls mittels einer manipulationssicheren Dokumentation denkbar.
Im Rahmen der Realisierung des SouveMed-Datentreuhandmodells stehen hierbei folgende wissenschaftliche und technische Teilziele im Mittelpunkt:
Konzeption und Aufbau der Datentreuhänderplattform: Zur Verwaltung der Datenverwaltungseinheiten durch einen Datentreuhänder muss eine Repository zur Ablage, Aufbereitung, Vermittlung, und Bereitstellung konzipiert und umgesetzt werden. Hierbei muss geklärt werden, inwiefern solch ein Repository technisch und organisatorisch aufgebaut werden kann und inwiefern sich dezentrale Ansätze hierfür eignen. Hierzu sollen existierende dezentrale und zentralistische Ansätze evaluiert werden und das geeignetste in eine Systemarchitektur überführt werden. Zusätzlich müssen die Datentreuhänderfunktionen in eine solche Systemarchitektur integriert und abgebildet werden. Diese umfassen Dienste zur Auffindbarkeit der Daten in der Datenablage basierend auf Metadaten/-tags, Dienste zur Aufbereitung der Datenqualität, die Verwaltung der Nutzungsabsichten der Datennutzer sowie der dazugehörige Matching-Service zur Weiterleitung der Nutzungsanfragen inklusive Nutzungsabsichten an die Datenverwaltungseinheiten. Verhandlungen über Datenzugriffe und Dienstleistungen sollen im System evaluiert werden, indem die Eignung zur Nutzung Blockchain-basierter Votingverfahren untersucht und deren konzeptionelle Einbettung in das System betrachtet wird. Einschließlich, aber nicht nur beschränkt auf die Datentreuhänderplattform sollen für alle prototypischen Entwicklungen demonstratorhafte Softwarebausteine und umfassende Leitfäden zum Lösungskonzept entwickelt werden, welche einfache, modulare und wiederverwendbare Elemente für Organisationen bereitstellt, die jene als Rahmenwerke für künftige Entwicklungen nutzen können.
Anbindung heterogener Datenhaltungs- und IT-Systeme über eine geeignete Infrastruktur: Zur Demonstration der Datentreuhänderplattform sollen die aktuell bei Datenerzeugenden und -nutzenden vorhandenen Datenhaltungs- und -verarbeitungssysteme in klinischen Einrichtungen beispielhaft an denen der UKF an die Datentreuhänderplattform angebunden werden. Hierzu müssen die dort vorherrschenden Schnittstellen, Datenformate und Protokolle analysiert und eine standardisierte Methode zur Anbindung geschaffen werden.
Erweiterte und anwendungsfallspezifische Datenverwaltungseinheiten: Kapselung der Daten in einer Verwaltungseinheit, in interoperablen Formaten (z.B. HL7 FHIR, SNOMED CT, EDF, LOINC) und vor unbefugten Zugriffen geschützt. Hierzu sollen vorhandene Frameworks zur Containerisierung evaluiert und anschließend um folgende Funktionen erweitert werden: Schnittstellen zur Befüllung, Abfrage & Analyse der Daten; interoperable Abbildung der aggregierten Daten; Verschlüsselung; Anhängen von Nutzungsbedingungen & Metadaten/-tags zur Auffindbarkeit (FAIR-Data Prinzip: Findable, Accessible, Interoperable, Reusable); Service zur Meldung, Validierung und Kontrolle von Zugriffsanfragen; Integration von De-Identifikationsmethoden und Wahl von Datenqualitätsindikatoren, Integration dieser in die Datenverwaltungseinheit. Datenqualitätsindikatoren und -formate sollen zur Standardisierung an denen von TMF und MII orientieren. Die anschließende Auditierung aller Zugriffe und Verarbeitungsschritte die auf eine Datenverwaltungseinheit erfolgen, ermöglichen die Kontrolle über die Daten auch über den eigenen Vertrauenshorizont hinaus. Hierfür kann Blockchain-/Distributed Ledger Technologie (DLT) in Kombination mit dem in der Datenverwaltungseinheit integrierten Service zur Meldung dienen. Alle Anfragen an die Datenverwaltungseinheit können direkt verschlüsselt in einer Blockchain hinterlegt oder über einen Hash auf dem Off-Chain Speicherort (z.B. IPFS, Dat, Solid Pods) manipulationssicher protokolliert werden. Die Daten können anschließend mittels der Datenverwaltungseinheit zur Verfügung gestellt werden oder einer sicheren Ausführungsumgebung beim Datentreuhänder für mögliche technische Weiterverarbeitungsmöglichkeiten zur Verfügung gestellt werden.
Containerisierte Datenverarbeitungsverfahren: Aufbau einer Analyseplattform zur Nutzung und Verwertung der Daten, aufbauend auf dem vorhandenen Curious-Container-Ansatz. Jenen gilt es so zu erweitern, dass die hierdurch unterstützten Analyseverfahren für Schlafdaten über Schnittstellen auf die Datenverwaltungseinheit zugreifen können. Möglichkeiten der De-Identifikation werden erarbeitet zur Verwendung der Daten in pseudonymisierter oder anonymisierter Form (Abhängig vom aktuellen Einwilligungsstatus des Datengebenden). Hierbei sollen die unterschiedlichen Analyseergebnisse der beiden Möglichkeiten hinsichtlich ihres Nutzen und Mehrwertes zur Beantwortung von Forschungsfragen in der Schlafmedizin bewertet werden, um die Auswirkungen der initialen Entscheidung eines Datengebenden gemäß einer gewünschten Anonymisierung oder Pseudonymisierung zu verdeutlichen.
Anwendung zur Verwaltung der eigenen Datenverwaltungseinheiten durch Datengebenden: Ein zentrales Element stellt die patientenzentrierte Verwaltung und Bereitstellung der Daten für die Forschung dar und die damit verbundene Abgabe einer Einwilligungserklärung. Hierzu soll eine mobile Anwendung entwickelt werden, welche dies digital abbildet und dem Datengebenden einen Überblick über alle seine Datenverwaltungseinheiten und deren Nutzung in der Forschung liefert. Der Datengeber soll die Souveränität über seine Daten erhalten, sollte jedoch mit der damit verbundenen Verantwortung und Aufgaben nicht überfordert werden. Hierbei spielt die Usability und nutzerfreundliche Abbildung jener durch den Datengeber gesteuerten Prozesse eine Rolle, um zu ermöglichen das Datengeber die geschaffene Transparenz und Informationen adäquat verarbeiten kann. Dementsprechend soll eine Beteiligung der Datengebenden durchgehend stattfinden. Insbesondere ist die Visualisierung der Daten und ihre laiengerechte Erklärung zu erarbeiten, damit informiertes Einverständnis gegeben werden kann. Eine bedarfsgerechte Granularität des Einverständnisses muss festgelegt werden (Einverständnis für bestimmte oder alle zusammengehörigen Daten, für einzelne oder Gruppen von Datennutzern).
Evaluation und Erprobung der Datenökosystems mit potentiellen Nutzern anhand eines realen Anwendungsszenarios: Eine Einbindung der Nutzenden soll durchgehend erfolgen, beginnend bei Nutzerstudien und Workshops zur Erhebung von Anforderungen, über Zwischenevaluationen anhand erster Demonstratoren (Mocks) und Prototypen bis hin zur Evaluation des Gesamtsystems. Hierdurch soll die kontinuierliche Partizipation der unterschiedlichen Akteure geschaffen werden, so dass diese Erkenntnisse iterativ in die zu entwickelten Lösungen einfließen können und ein gesamtheitliches Datenökosystem aufgebaut werden kann. Im Rahmen des Vorhabens sollen dementsprechend u.a. folgende Forschungsfragen untersucht werden:
- Wie können verschiedene Zugriffspunkte und Verarbeitungsschritte zur Erhöhung der Datenqualität der gespendeten Daten im Datenspendekreislauf mit Hilfe einer technischen Lösung abgebildet, validiert, nachvollzogen und gesteuert werden?
- Wie kann der Datengeber in den gesamten Datenspendekreislauf involviert werden, so dass dieser selbstbestimmt über seine Gesundheitsdaten entscheiden kann, sowie die geschaffene Transparenz und die vorhandenen Informationen adäquat verarbeiten kann?
- Welche Möglichkeiten zur containerbasierten Datenverarbeitung gibt es zur Verarbeitung der schlafbezogenen Daten aus Sicht des Datennutzenden?
Einbeziehung der ethischen, rechtlichen und sozialen Implikationen (ELSI): Die ELSI-Aspekte sollen in der Konzeption-, Entwicklungs- und Evaluationsphase adressiert werden. Besonders die ethischen Implikationen einer potentiellen Datenfreigabeoption und die damit verbundenen Patienteneinwilligungen und -informationen müssen in dem Umfang ausgearbeitet und kommuniziert werden, dass eine informierte Einwilligung und Klarheit über die Nutzung der Daten auch Laien verständlich wird. Das schließt Informationen darüber ein, welche Dinge aus den Daten ersichtlich sind (etwa Schlaf- und Wachzeiten, auch nächtlicher Toilettengang), aber auch welche nicht ersichtlich sind (wie Trauminhalte).
Betrachtung rechtlicher Rahmenbedingungen: Aus rechtlicher Sicht sollen die Anforderungen der EU-DSGVO sowie des Telekommunikation-Telemedien-Datenschutzgesetz (TTDSG) und bereichsspezifischen Datenschutzbestimmungen an Datenschutz und -privatheit entsprechend der Datenschutzgrundsätze im Umgang mit den sensiblen Gesundheitsdaten adressiert werden. Insbesondere die Gestaltung von Patienteneinwilligungen und -informationen zur Verarbeitung von Daten ist ein sensibles Thema, sowie der Einbezug von Security- und Privacy-By-Design-Ansätze bei der Lösungsentwicklung sollen Beachtung finden.

Das FZI Forschungszentrum Informatik am Karlsruher Institut für Technologie ist eine gemeinnützige Einrichtung für Informatik-Anwendungsforschung und Technologietransfer. Es bringt die neuesten wissenschaftlichen Erkenntnisse der Informationstechnologie in Unternehmen und öffentliche Einrichtungen und qualifiziert junge Menschen für eine akademische und wirtschaftliche Karriere oder den Sprung in die Selbstständigkeit. Das FZI Forschungszentrum Informatik am Karlsruher Institut für Technologie ist eine gemeinnützige Forschungstransfereinrichtung des Landes Baden-Württemberg, das für seine Geschäfts- und Forschungspartner Lösungen für innovative Produkte, Dienstleistungen und Geschäftsprozesse entwickelt. Geführt von Professoren verschiedener Fakultäten entwickeln die Forschungsgruppen am FZI interdisziplinär für ihre Auftraggeber Konzepte, Software-, Hardware- und Systemlösungen und setzen die gefundenen Lösungen prototypisch um. Wissenschaftliche Exzellenz und gelebte Interdisziplinarität sind somit in der Organisation verankert.
Alle Bereiche des FZI sind nach DIN EN ISO 9001:2008 zertifiziert. Hauptsitz ist Karlsruhe. Das FZI ist mit einer Außenstelle in Berlin vertreten.
Die HTW Berlin ist mit fast 14.000 Studierenden die größte Berliner Hochschule für angewandte Wissenschaften. In das interdisziplinäre Umfeld von 70 Studiengängen der HTW fügt sich die Angewandte Informatik als forschungsstarker Studiengang mit interdisziplinären Schwerpunkten, darunter der Gesundheitsinformatik. Die diesbezüglichen Forschungs- und Transfertätigkeiten sind in der Wissenschaftlichen Einrichtung Centrum für Biomedizinische Bild- und Informationsverarbeitung (CBMI) gebündelt. Durch ein breites Netzwerk sowohl in anderen Forschungseinrichtungen als auch in der freien Wirtschaft stärkt das CBMI den Transfer der angewandten Forschungsergebnisse in die Gesundheitswirtschaft

Das Universitätsklinikum Freiburg (UKF) ist ein Krankenhaus der Maximalversorgung mit 2180 Betten und zugleich der ausgezeichneten medizinischen Forschung. Die Schlafmedizinische Station der Abteilung für Klinische Psychologie und Psychophysiologie an der Klinik für Psychiatrie und Psychotherapie ist ein von der Deutschen Gesellschaft für Schlafforschung und Schlafmedizin (DGSM) akkreditiertes Schlaflabor mit 5 Schlaflaborplätzen und verfügt über eine 30-jährige Erfahrung in der Diagnostik und Therapie von Schlafstörungen.